Pemasangan & Konfigurasi Hadoop (Distribusi Pseudo) dan Latihan: WordCount2
VM Fedora
Saya cuba menyediakan Hadoop dengan kluster nod tunggal (Single Node Cluster) di VM Fedora. Pada hemat saya, mungkin tak akan mampu lagilah untuk saya usahakan penyediaan pengoperasian berdistribusi penuh bersama Kerberos sebagai kaedah pengesahan kerana Hadoop memerlukan sistem yang berprestasi tinggi.
Berdasarkan jawapan yang disediakan oleh platform-platform AI, saya ringkaskan syarat minimum sistem untuk mengehoskan Hadoop dengan kluster nod tunggal, memandangkan perkakasan komputer riba saya hanya mampu menampung sumber berskala kecil:
| Perkakasan | Minimum | Saranan | VM saya |
|---|---|---|---|
| RAM | 4GB | 8GB | 6GB |
| CPU | 2 cores | 4 cores | 8 cores |
| Storan | 50GB | 100GB | 80GB |
Versi Java: Java 8 (dimuat turun dari laman web Oracle)
Pengguna: hadoop
Rujukan untuk contoh perintah baris bagi menjalankan VM disediakan melalui pautan yang tersenarai di bahagian bawah halaman ini.
Walau bagaimanapun, terdapat perbezaan dalam cara saya bersambung ke Internet kerana saya menggunakan kaedah manual melalui peranti
TUNTAP dengan alamat IP statik, berbanding kaedah biasa yang menetapkan alamat IP secara automatik melalui DHCP. Contoh konfigurasi boleh didapati dalam penulisan saya yang bertajuk "Pemahaman Asas Kerberos dan SSH."Eksperimen seterusnya yang dirangka:
- Konfigurasi yang betul untuk pengguna
hdfs,yarndanmapred. Lihat "Panduan Hadoop Mod Selamat (Kerberos) pada Nod Tunggal."
SSH setup (sistem Hos & VM)
Suka untuk saya gunakan resolusi hostname dengan mengikat alamat IP mesin saya (IPv4) kepada nama hos yang ditetapkan dengan menyunting fail /etc/hosts seperti berikut:
/etc/hosts192.168.0.100 single.cluster.loc fedovm ~/.ssh/config## VMs
# with tuntap (kernel virtual network device)
Host fedovm
HostName single.cluster.loc
User hadoopOh, ya! Saya set up pelayan Kerberos dan log masuk melalui sambungan SSH dengan kaedah GSSAPI di sini, sebagaimana yang saya muatkan dalam hantaran blog terdahulu bertajuk “Pemahaman Asas Kerberos dan SSH.” Hal ini bermaksud, VM ini bertindak sebagai pelayan dan klien Kerberos dalam masa yang sama.
Pastikan sudah memasang pakej openssh dan servis sshd sudah dimulakan sebelum meneruskan proses di bawah ini yang juga memberikan output selanjutnya:
bashssh -v fedovm ... Authenticated to single.cluster.loc ([192.168.0.100]:22) using "gssapi-keyex". ...
Pakej prasyarat
Pasang pakej
pdsh. Pakej ini amat dicadang pemasangannya olehHadoopuntuk mendapatkan pengurusan sumberSSHyang lebih baik. Saya pasang dari sumber dengan mengklon repositori GitHub-nya untuk mendapatkan konfigurasi bersama SSH yang tidak disediakan sebagai tetapan lalai oleh Fedora melalui repo rasminya.Pasang pakej-pakej yang diperlukan untuk binaan dari sumber:
bashsudo dnf install autoconf libtoolKlon dan bina:
bash# inside $HOME mkdir Build && cd Build # Clone the repository. git clone https://github.com/chaos/pdsh.git # Get into the directory. cd pdsh # Run the following commands to compile and install. (Good Luck!) ./bootstrap ./configure --with-ssh sudo make sudo make install ### Confirm the installation by verifying its version. pdsh -Vpdsh-2.35 rcmd modules: ssh,rsh,exec (default: rsh) misc modules: (none)
Pemasangan Java:
Muat turun
Java SE Development Kit 8u441(fail jdk-8u441-linux-x64.rpm) yang memerlukan pengguna untuk log masuk ke akaun Oracle dan pasang dengan perintah baris:bashsudo dnf install jdk-8u441-linux-x64.rpm
Pemasangan Hadoop
Muat turun pakej binari dari laman web rasmi Hadoop dan ekstrak pakej kompres itu ke direktori rumah pengguna dengan perintah
tar:bashwget -P ~/Downloads https://dlcdn.apache.org/hadoop/common/current/hadoop-3.4.1.tar.gz # contoh tar -xvzf Downloads/hadoop-3.4.1.tar.gzEdit fail
.bashrcuntuk menambah laluan:~/.bashrcexport JAVA_HOME="/usr/lib/jvm/jdk-1.8.0_441-oracle-x64" export HADOOP_HOME="$HOME/hadoop-3.4.1" export HADOOP_CONF_DIR="$HADOOP_HOME/etc/hadoop" export HADOOP_CLASSPATH="$HADOOP_HOME/share/hadoop/tools/lib/*:$HADOOP_CONF_DIR/*" export PATH="$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH"Aktifkan perubahan.
bashsource ~/.bashrc
Konfigurasi Hadoop
hadoop-env.sh
$HADOOP_CONF_DIR/hadoop-env.shexport JAVA_HOME="/usr/lib/jvm/jdk-1.8.0_441-oracle-x64"core-site.xml
$HADOOP_CONF_DIR/core-site.xml<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://fedovm:9000</value>
</property>
</configuration>hdfs-site.xml
$HADOOP_CONF_DIR/hdfs-site.xml<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>namenodes</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>fedovm:9870</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>fedovm:9868</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>datanodes</value>
</property>
<property>
<name>dfs.datanode.http.address</name>
<value>fedovm:9864</value>
</property>
</configuration>yarn-site.xml
$HADOOP_CONF_DIR/yarn-site.xml<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>fedovm</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>fedovm:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME</value>
</property>
<property>
<name>yarn.nodemanager.webapp.address</name>
<value>fedovm:8042</value>
</property>
</configuration>mapred-site.xml
$HADOOP_CONF_DIR/mapred-site.xml<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>fedovm:19888</value>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/mr-history/tmp</value>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/mr-history/done</value>
</property>
</configuration>workers
$HADOOP_CONF_DIR/workersfedovmMulakan servis
Format
NameNode:bashhdfs namenode -formatMulakan
daemonHDFS dan YARN (contoh output):bashstart-dfs.sh && start-yarn.sh && mapred --daemon start historyserverStarting namenodes on [fedovm] Starting datanodes Starting secondary namenodes [fedovm] Starting resourcemanager Starting nodemanagers
Semak proses-proses yang berlangsung dan contoh output:
bashjps2758 Jps 1639 NameNode 1970 SecondaryNameNode 1749 DataNode 2190 ResourceManager 2289 NodeManager 2671 JobHistoryServer
Praktis 1
(using a built-in example program called "grep")
Tambah direktori pengguna ke dalam Distributed filesystem:
bash# Return to $HOME cd ~ # Create the user directory. hdfs dfs -mkdir -p /user/hadoop # Create the directory for the test. hdfs dfs -mkdir -p p1_intro/input # Copy files from the local fs to the distributed fs. hdfs dfs -put $HADOOP_CONF_DIR/*.xml p1_intro/input # Run a MapReduce job. hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.4.1.jar \ grep p1_intro/input p1_intro/output 'dfs[a-z.]+'Semak direktori:
bashhdfs dfs -ls -C p1_intro hdfs dfs -ls -C p1_intro/outputp1_intro/output/_SUCCESS p1_intro/output/part-r-00000
Output:
bashhdfs dfs -cat p1_intro/output/part-r-000001 dfsadmin 1 dfs.replication 1 dfs.namenode.secondary.http 1 dfs.namenode.name.dir 1 dfs.namenode.http 1 dfs.datanode.http.address 1 dfs.datanode.data.dir
Atau salin fail pengeluaran ke sistem lokal:
bash# OR copy the outputs from the distributed fs to the local fs for observation. hdfs dfs -get p1_intro/output output1Sambung dengan latihan seterusnya.
Praktis 2 (WordCount2)
Penyediaan:
bash# Create the directories for Practice 2. hdfs dfs -mkdir -p p2_wordcount2/input # Create two files; file1 & file2. touch file1 file2 # residing in the local fs. echo 'Hello World, Bye World!' > file1 echo 'Hello Hadoop, Goodbye to hadoop.' > file2 # Move the files from the local fs to the distributed fs. hdfs dfs -moveFromLocal file1 p2_wordcount2/input hdfs dfs -moveFromLocal file2 p2_wordcount2/input ### Confirm the moved files. hdfs dfs -ls -C p2_wordcount2/inputp2_wordcount2/input/file1 p2_wordcount2/input/file2
Penyediaan awal untuk menggunakan ciri
DistributedCachedalam dua kerja terakhir nanti:bashtouch patterns.txt # Create patterns.txt with specified lines. echo -e '\\.\n\\,\n\\!\nto' > patterns.txt ### Confirm the contents of patterns.txt. cat patterns.txt\. \, \! to
Pindahkan fail di atas dari sistem lokal ke sistem distribusi:
bashhdfs dfs -moveFromLocal patterns.txt p2_wordcount2 ### Display directories and files in p2_wordcount2. hdfs dfs -ls -C p2_wordcount2p2_wordcount2/input p2_wordcount2/patterns.txt
Salin kod
Java, “Example: WordCount v2.0 Source Code” ini ke dalam failWordCount2.java(available in Hadoop documentation as Tutorial). Atau simpan pautan “WordCount2.java” ini sebagai kod sumberJava.Semak kod terlebih dahulu dengan perintah
less:bashless WordCount2.javaPenyusunan:
bash# Compile the WordCount2 Java source code. hadoop com.sun.tools.javac.Main WordCount2.java # Package the compiled Java classes into a JAR file. jar cf wc.jar WordCount*.class ### List compiled files and jars. ls | grep -E 'wc\.jar|WordCount2.*\.class'wc.jar WordCount2$IntSumReducer.class WordCount2$TokenizerMapper$CountersEnum.class WordCount2$TokenizerMapper.class WordCount2.class
Jalankan kerja
MapReducetanpa ciriDistributedCache:bashhadoop jar wc.jar WordCount2 \ p2_wordcount2/input p2_wordcount2/output1 ### Check generated files and view output. hdfs dfs -cat p2_wordcount2/output1/part-r-00000Bye 1 Goodbye 1 Hadoop, 1 Hello 2 World! 1 World, 1 hadoop. 1 to 1
Perhatikan perubahan output untuk proses
MapReducedi bawah:
= dengan menetapkan sensitiviti bagi jenis huruf kepada benar;
= dengan mengaktifkan ciriDistributedCachemelalui opsyen-skip.bashhadoop jar wc.jar WordCount2 -Dwordcount.case.sensitive=true \ p2_wordcount2/input p2_wordcount2/output2 \ -skip p2_wordcount2/patterns.txt ### Observe the output. hdfs dfs -cat p2_wordcount2/output2/part-r-00000Bye 1 Goodbye 1 Hadoop 1 Hello 2 World 2 hadoop 1
Begitu juga untuk proses
MapReducedi bawah:
= dengan menetapkan sensitiviti bagi jenis huruf kepada tidak benar;
= dengan mengaktifkan ciriDistributedCachemelalui opsyen-skip.bashhadoop jar wc.jar WordCount2 -Dwordcount.case.sensitive=false \ p2_wordcount2/input p2_wordcount2/output3 \ -skip p2_wordcount2/patterns.txt ### Observe the output. hdfs dfs -cat p2_wordcount2/output3/part-r-00000bye 1 goodbye 1 hadoop 2 hello 2 world 2
Paparan web di:
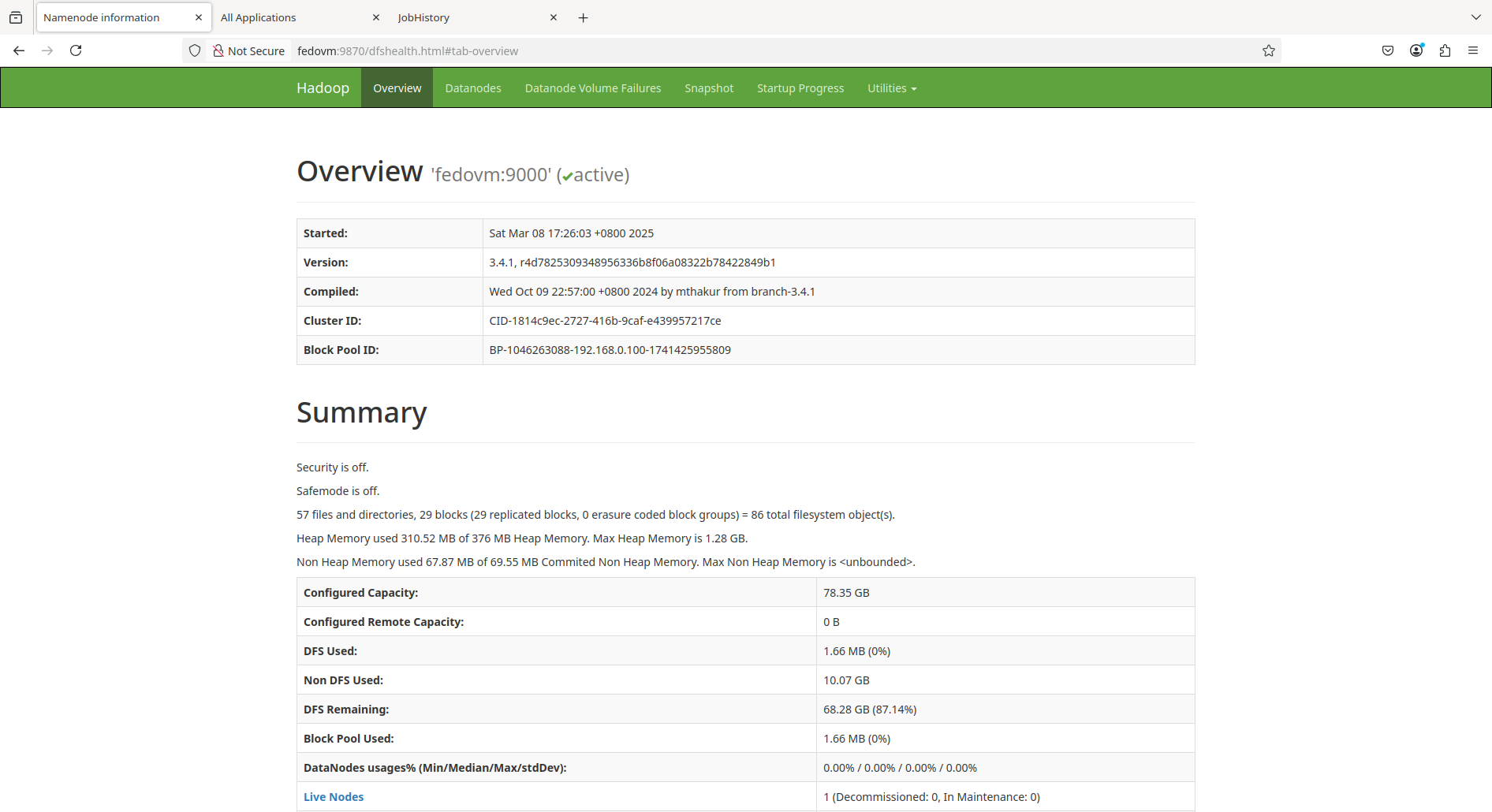
NameNode: http://fedovm:9870/
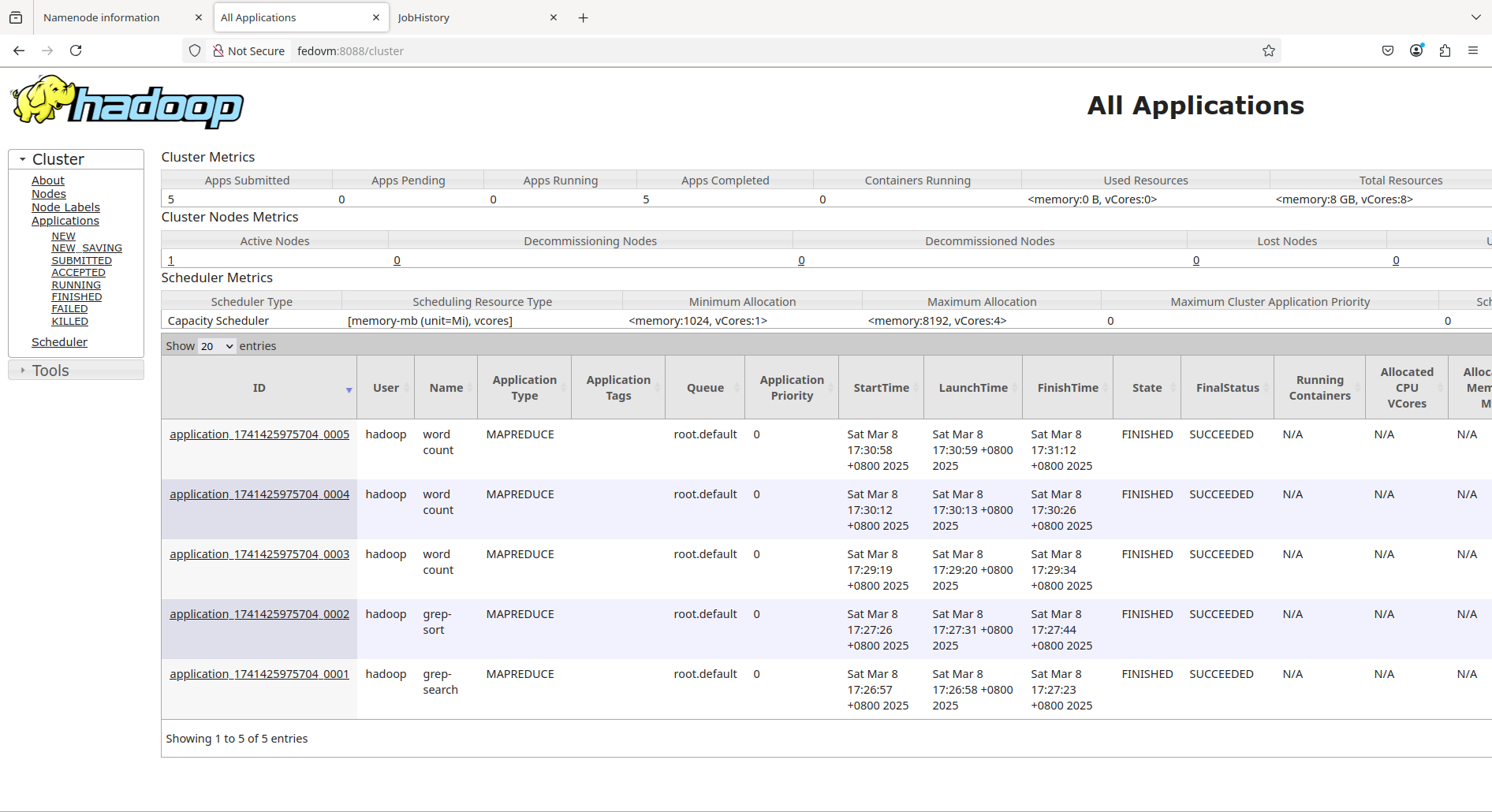
ResourceManager: http://fedovm:8088/
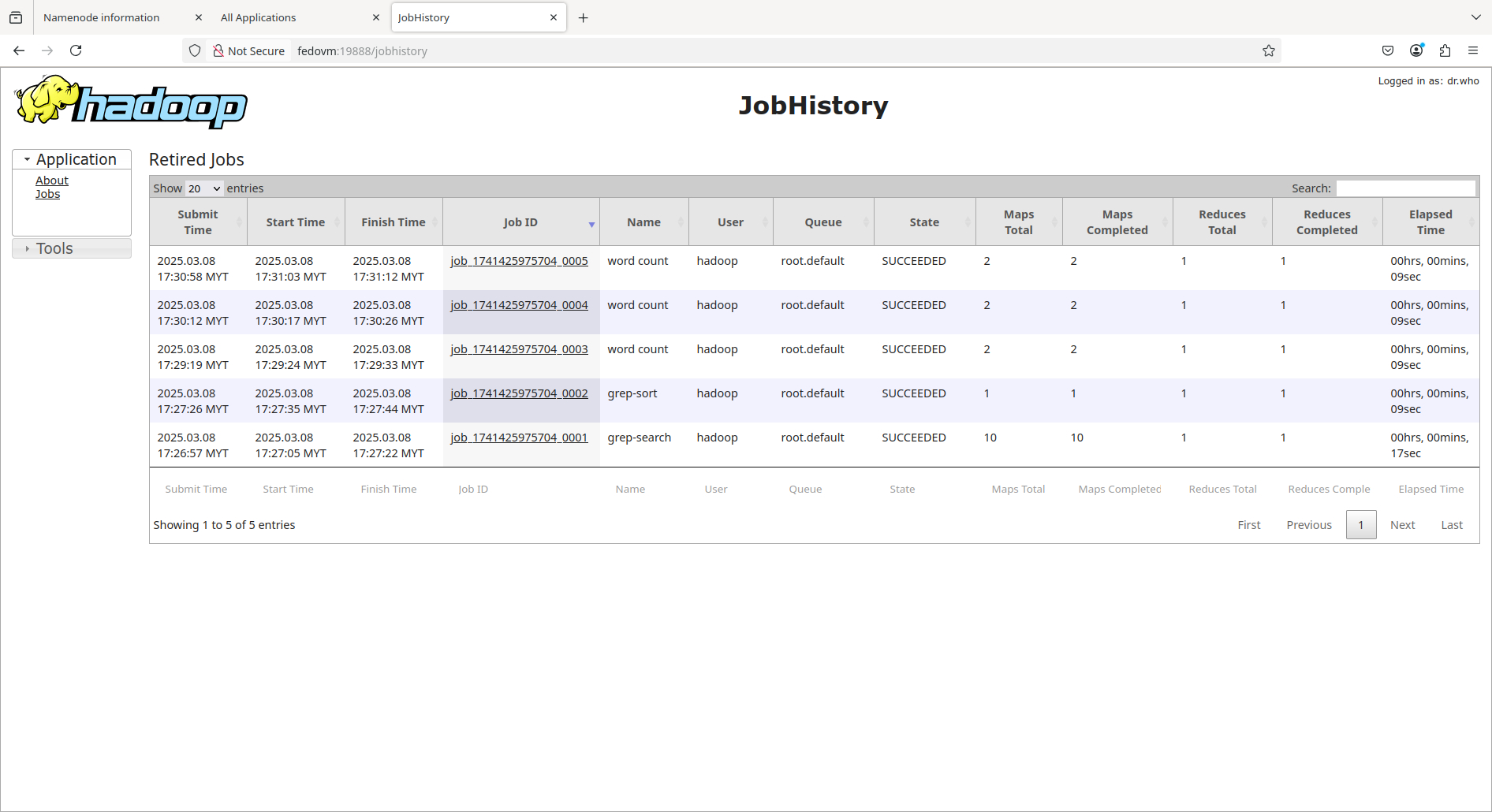
MapReduce JobHistory Server: http://fedovm:19888/
Setelah selesai, hentikan kesemua daemon:
bashmapred --daemon stop historyserver && stop-yarn.sh && stop-dfs.sh
exitTentang Blog & Penulis
Linux dan perisian sumber terbuka, Virtual Machine, serta Typesetting system.Full Stack DevelopmentAnalisis Data
Sumber dari Wallpaper Cave.