Sesungguhnya, tiada daya hamba mahu bermukaddimah panjang. Kelelahan hamba dalam mendapatkan objektif dengan lancar dek banyaknya tutorial yang sudah begitu lama dan terkebelakang untuk diikuti.
Alhamdulillah, tanpa mengenal putus asa, beroleh jua hamba sedikit kelegaan apabila mencapai objektif dengan kembali merujuk pada dokumentasi rasmi yang disediakan oleh Apache Hadoop.
Pasang pakej pdsh sama ada dari AUR atau GitHub. Pakej ini amat dicadang pemasangannya oleh Hadoop untuk mendapatkan pengurusan sumber SSH yang lebih baik. Saya pasang dari sumber dengan mengklon repositori GitHub-nya:
# Clone the repository.
git clone https://github.com/chaos/pdsh.git
# Get into the directory.
cd pdsh
# Run the following commands to compile and install. (Good Luck!)
./bootstrap
./configure
sudo make
sudo make install
### Confirm the installation by verifying its version.
pdsh -Vpdsh-2.35 rcmd modules: rsh,exec (default: rsh) misc modules: (none)
hadooppseudo bagi tujuan pembangunan sahaja. Saya suka gunakan resolusi hostname untuk mengikat alamat IP lokal saya (IPv4) kepada nama hos yang ditetapkan dengan menyunting fail /etc/hosts seperti berikut:192.168.0.123 single-nodehadoop. Contoh (arahan mungkin berbeza bagi distribusi selain Arch):sudo useradd -m -U -G wheel -s /usr/bin/zsh hadoop
# Set passwd for the user.
sudo passwd hadoop
# Switch to user 'hadoop'.
su - hadoop-m untuk menambah direktori pengguna i.e. /home/hadoop.-U untuk menambah pengguna sebagai kumpulan juga i.e. hadoop.-G sebagai cara untuk tambah pengguna ke dalam kumpulan pilihan.-s bagi menentukan jenis shell.*️⃣ Masukkan pengguna hadoop ini ke dalam kumpulan sudo.
ssh localhost
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keysEkstrak pakej kompres itu ke direktori pengguna dengan perintah tar:
tar -xvzf hadoop-3.3.6.tar.gzEdit fail .zshrc untuk menambah laluan:
export JAVA_HOME="/usr/lib/jvm/java-8-openjdk"
export HADOOP_HOME="$HOME/hadoop-3.3.6"
export HADOOP_CLASSPATH="$JAVA_HOME/lib/tools.jar"
export PATH="$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin"Aktifkan perubahan. Edit fail .zshrc untuk menambah laluan dan masuk ke dalam direktori:
source ~/.zshrc
cd $HADOOP_HOME/etc/hadoophadoop-env.sh dan tambahkan baris di bawah:export JAVA_HOME="/usr/lib/jvm/java-8-openjdk"core-site.xml:<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xml:<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>mapred-site.xml:<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>yarn-site.xml:<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME</value>
</property>
</configuration>NameNode:hdfs namenode -formatdaemon HDFS dan YARN (contoh output):start-dfs.sh && start-yarn.shStarting namenodes on [localhost] Starting datanodes Starting secondary namenodes [archlinux] Starting resourcemanager Starting nodemanagers
sudo jps191043 NameNode 192563 Jps 191953 NodeManager 191460 SecondaryNameNode 191199 DataNode 191791 ResourceManager
grep)hdfs dfs -mkdir -p /user/name # Create the user directory.
hdfs dfs -ls /user/name # The dir would still be empty.
hdfs dfs -mkdir -p /user/name/p1_intro/input # Directories for the test.
# (local fs environment)
cd $HADOOP_HOME
# Copy files from the local fs to the distributed fs.
hdfs dfs -put etc/hadoop/*.xml /user/name/p1_intro/input
# Run a MapReduce job.
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar \
grep /user/name/p1_intro/input /user/name/p1_intro/output \
'dfs[a-z.]+'hdfs dfs -ls -C /user/name/p1_intro
hdfs dfs -ls -C /user/name/p1_intro/output/user/name/p1_intro/output/_SUCCESS /user/name/p1_intro/output/part-r-00000
hdfs dfs -cat /user/name/p1_intro/output/part-r-000001 dfsadmin 1 dfs.replication
# OR copy the outputs from the distributed fs to the local fs for observation.
hdfs dfs -get /user/name/p1_intro/output output1daemon YARN serta HDFS dan mula semula:stop-yarn.sh && stop-dfs.sh
exit
# Next login.
ssh localhost
start-dfs.sh && start-yarn.shcd ~ # Return to $HOME dir if didn't exit from SSH previously.
# Create the directories for Practice 2.
hdfs dfs -mkdir -p /user/name/p2_wordcount2/input
# Create two files; file1 & file2.
touch file1 file2 # residing in the local fs.
echo 'Hello World, Bye World!' > file1
echo 'Hello Hadoop, Goodbye to hadoop.' > file2
# Move the files from the local fs to the distributed fs.
hdfs dfs -moveFromLocal file1 /user/name/p2_wordcount2/input
hdfs dfs -moveFromLocal file2 /user/name/p2_wordcount2/input
### Confirm the moved files.
hdfs dfs -ls -C /user/name/p2_wordcount2/input/user/name/p2_wordcount2/input/file1 /user/name/p2_wordcount2/input/file2
DistributedCache dalam dua kerja terakhir nanti:touch patterns.txt
# Create patterns.txt with specified lines.
echo -e '\\.\n\\,\n\\!\nto' > patterns.txt
### Confirm the contents of patterns.txt.
cat patterns.txt\. \, \! to
hdfs dfs -moveFromLocal patterns.txt /user/name/p2_wordcount2
### Display directories and files in p2_wordcount2.
hdfs dfs -ls -C /user/name/p2_wordcount2/user/name/p2_wordcount2/input /user/name/p2_wordcount2/patterns.txt
Java ini ke dalam fail WordCount2.java (available in Hadoop documentation as Tutorial):import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.net.URI;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.util.StringUtils;
public class WordCount2 {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
static enum CountersEnum { INPUT_WORDS }
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
private boolean caseSensitive;
private Set<String> patternsToSkip = new HashSet<String>();
private Configuration conf;
private BufferedReader fis;
@Override
public void setup(Context context) throws IOException,
InterruptedException {
conf = context.getConfiguration();
caseSensitive = conf.getBoolean("wordcount.case.sensitive", true);
if (conf.getBoolean("wordcount.skip.patterns", false)) {
URI[] patternsURIs = Job.getInstance(conf).getCacheFiles();
for (URI patternsURI : patternsURIs) {
Path patternsPath = new Path(patternsURI.getPath());
String patternsFileName = patternsPath.getName().toString();
parseSkipFile(patternsFileName);
}
}
}
private void parseSkipFile(String fileName) {
try {
fis = new BufferedReader(new FileReader(fileName));
String pattern = null;
while ((pattern = fis.readLine()) != null) {
patternsToSkip.add(pattern);
}
} catch (IOException ioe) {
System.err.println("Caught exception while parsing the cached file '"
+ StringUtils.stringifyException(ioe));
}
}
@Override
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
String line = (caseSensitive) ?
value.toString() : value.toString().toLowerCase();
for (String pattern : patternsToSkip) {
line = line.replaceAll(pattern, "");
}
StringTokenizer itr = new StringTokenizer(line);
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
Counter counter = context.getCounter(CountersEnum.class.getName(),
CountersEnum.INPUT_WORDS.toString());
counter.increment(1);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
GenericOptionsParser optionParser = new GenericOptionsParser(conf, args);
String[] remainingArgs = optionParser.getRemainingArgs();
if ((remainingArgs.length != 2) && (remainingArgs.length != 4)) {
System.err.println("Usage: wordcount <in> <out> [-skip skipPatternFile]");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount2.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
List<String> otherArgs = new ArrayList<String>();
for (int i=0; i < remainingArgs.length; ++i) {
if ("-skip".equals(remainingArgs[i])) {
job.addCacheFile(new Path(remainingArgs[++i]).toUri());
job.getConfiguration().setBoolean("wordcount.skip.patterns", true);
} else {
otherArgs.add(remainingArgs[i]);
}
}
FileInputFormat.addInputPath(job, new Path(otherArgs.get(0)));
FileOutputFormat.setOutputPath(job, new Path(otherArgs.get(1)));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}less:less WordCount2.java# Compile the WordCount2 Java source code.
hadoop com.sun.tools.javac.Main WordCount2.java
# Package the compiled Java classes into a JAR file.
jar cf wc.jar WordCount*.class
### List compiled files and jars.
ls ~/ | grep -E 'wc\.jar|WordCount2.*\.class'wc.jar WordCount2$IntSumReducer.class WordCount2$TokenizerMapper$CountersEnum.class WordCount2$TokenizerMapper.class WordCount2.class
MapReduce tanpa ciri DistributedCache:hadoop jar wc.jar WordCount2 \
/user/name/p2_wordcount2/input /user/name/p2_wordcount2/output1
### Check generated files and view output.
hdfs dfs -cat /user/name/p2_wordcount2/output1/part-r-00000Bye 1 Goodbye 1 Hadoop, 1 Hello 2 World! 1 World, 1 hadoop. 1 to 1
MapReduce di bawah:DistributedCache melalui opsyen -skip.hadoop jar wc.jar WordCount2 -Dwordcount.case.sensitive=true \
/user/name/p2_wordcount2/input /user/name/p2_wordcount2/output2 \
-skip /user/name/p2_wordcount2/patterns.txt
### Observe the output.
hdfs dfs -cat /user/name/p2_wordcount2/output2/part-r-00000Bye 1 Goodbye 1 Hadoop 1 Hello 2 World 2 hadoop 1
MapReduce di bawah:DistributedCache melalui opsyen -skip.hadoop jar wc.jar WordCount2 -Dwordcount.case.sensitive=false \
/user/name/p2_wordcount2/input /user/name/p2_wordcount2/output3 \
-skip /user/name/p2_wordcount2/patterns.txt
### Observe the output.
hdfs dfs -cat /user/name/p2_wordcount2/output3/part-r-00000bye 1 goodbye 1 hadoop 2 hello 2 world 2

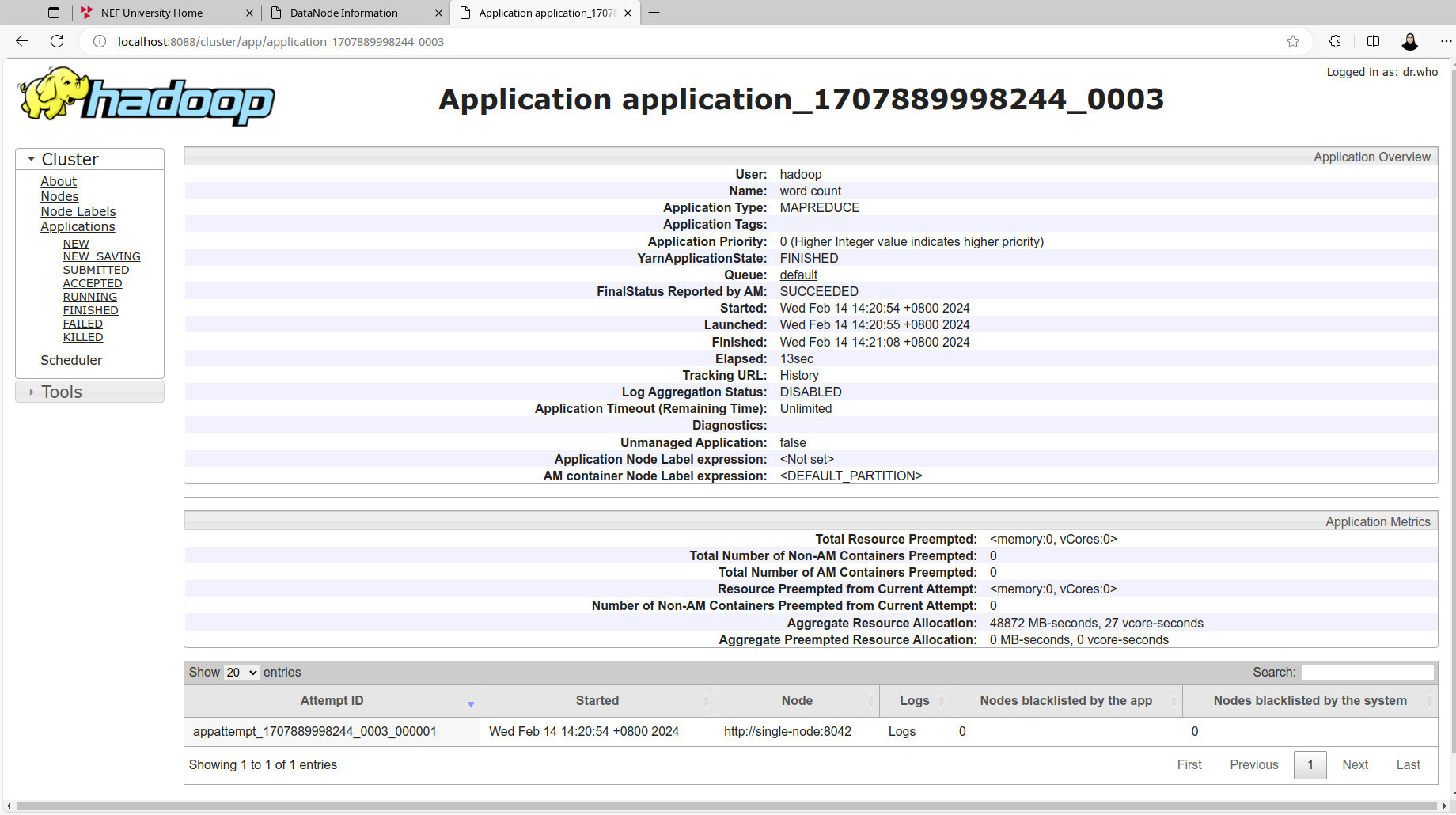
daemon YARN dan HDFS:stop-yarn.sh && stop-dfs.sh
exit